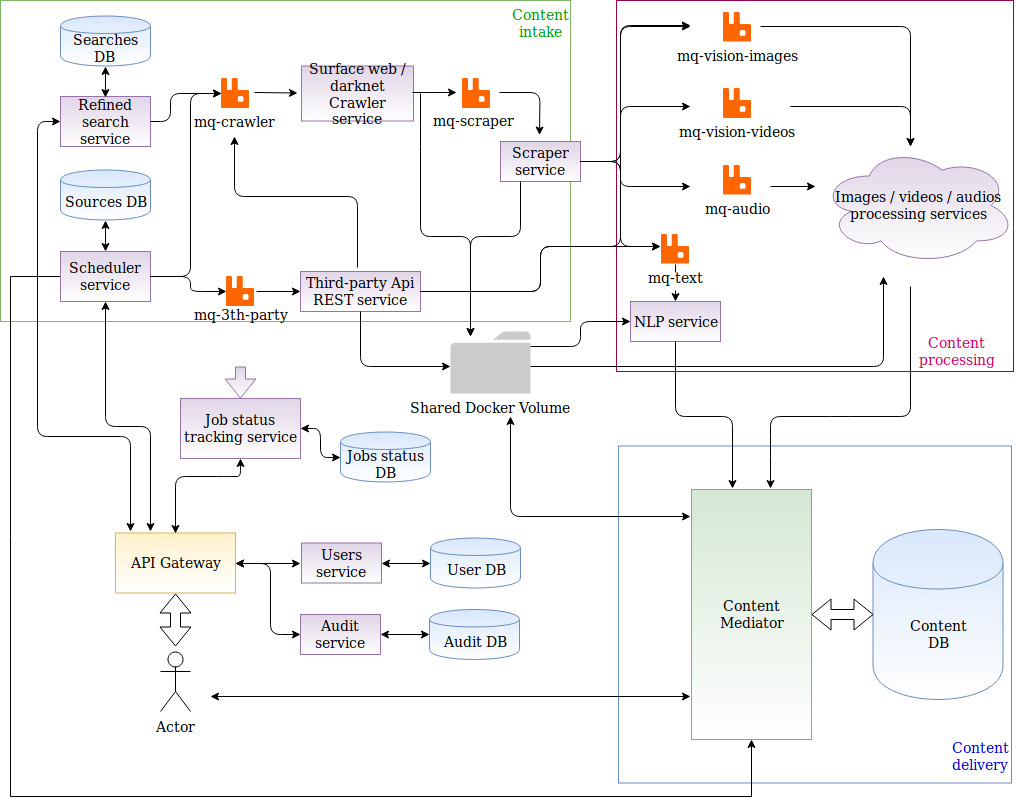












Multi purpose web crawler tool

A web crawler has been integrated in SPIRIT. The crawler adopts a master-slave architecture in order to manage incoming requests for downloading texts, images and videos from one or more Web sites.
An artificial dataset was created for testing the implemented crawler. A well-known open research dataset (in the area of Named Entity Recognition) was used to generate contents of the artificial Web sites. In order to not refer real identities, all the entities of the dataset (which is freely available at https://github.com/teropa/nlp/tree/master/resources/corpora/ieer) were replaced with entities from the Valcri dataset or with other dummy/fictional entities.